This project was completed as part of the Data Mining I course at the University of Pisa during the 2023-2024 academic year. The project involved an extensive analysis of a Spotify Tracks dataset containing over 15,000 songs, utilizing various data mining techniques to extract meaningful insights about music characteristics and patterns.
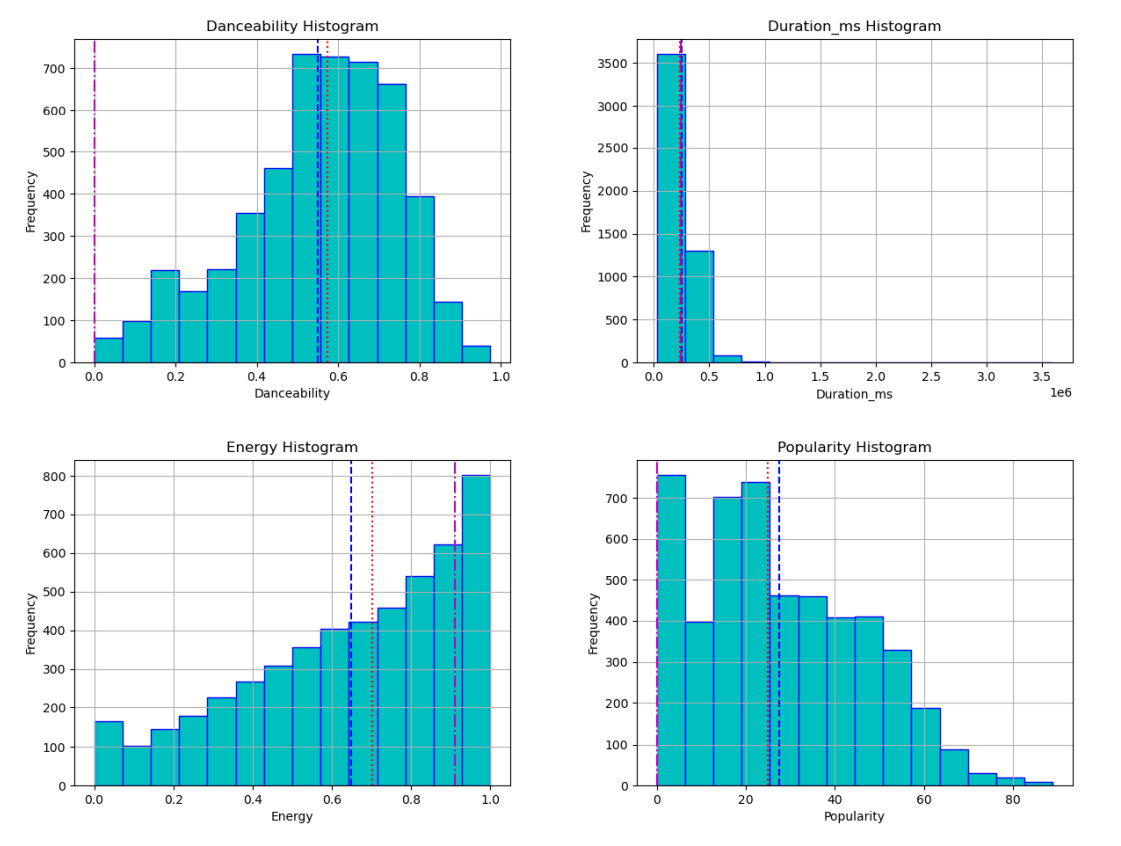
The project has five major analytical phases: data understanding and preparation, clustering analysis, classification modeling, regression techniques, and pattern mining. Each phase employed multiple algorithms and methodologies to explore the dataset from different analytical perspectives. The dataset included 24 attributes, extracted from the Spotify API, describing various aspects of songs, including duration, popularity, energy, danceability, acousticness, and musical genre.
Working collaboratively as a team of three students, we implemented data quality assessment procedures, handled missing values and outliers, performed feature engineering, and applied standardization techniques. The analytical work was conducted in Python, with the use of libraries such as scikit-learn, pandas, and mlxtend for applying various machine learning algorithms and data processing workflows.
This project provided hands-on experience with the complete data mining workflow, from raw data exploration to model evaluation and interpretation. One of the most significant lessons was understanding the critical importance of data quality assessment and preprocessing. Through comprehensive analysis of missing values, outliers, and semantic inconsistencies, I learned that cleaning data is not merely a preliminary step but a fundamental process that directly impacts all subsequent analysis. The decision to remove observations with multiple outlier attributes while preserving dataset size taught me the balance between data quality and quantity.
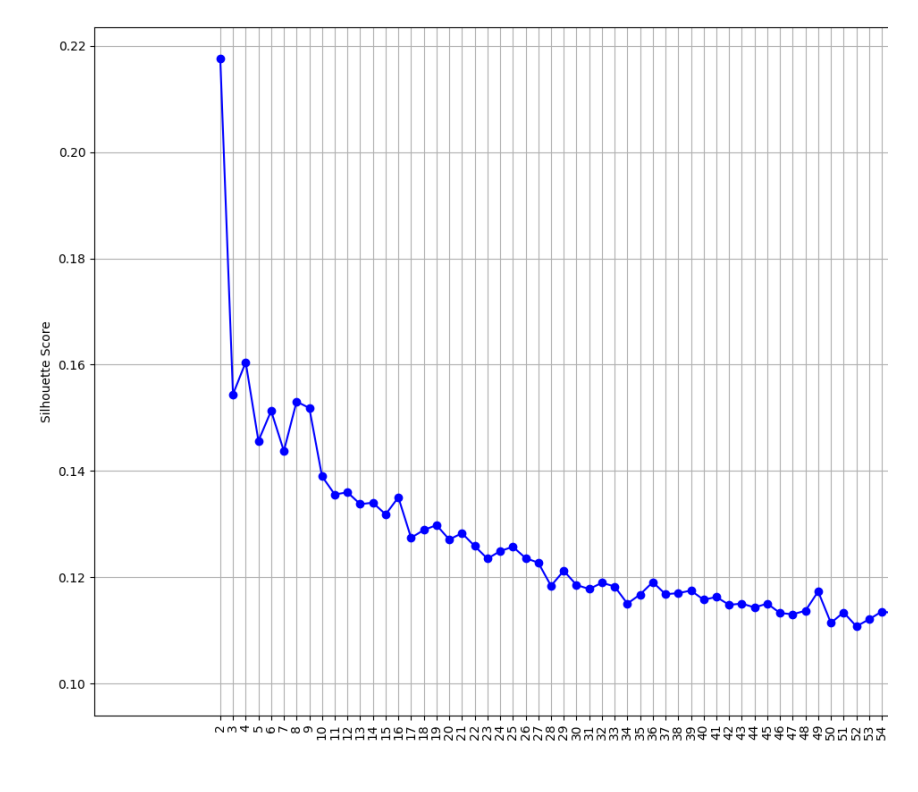
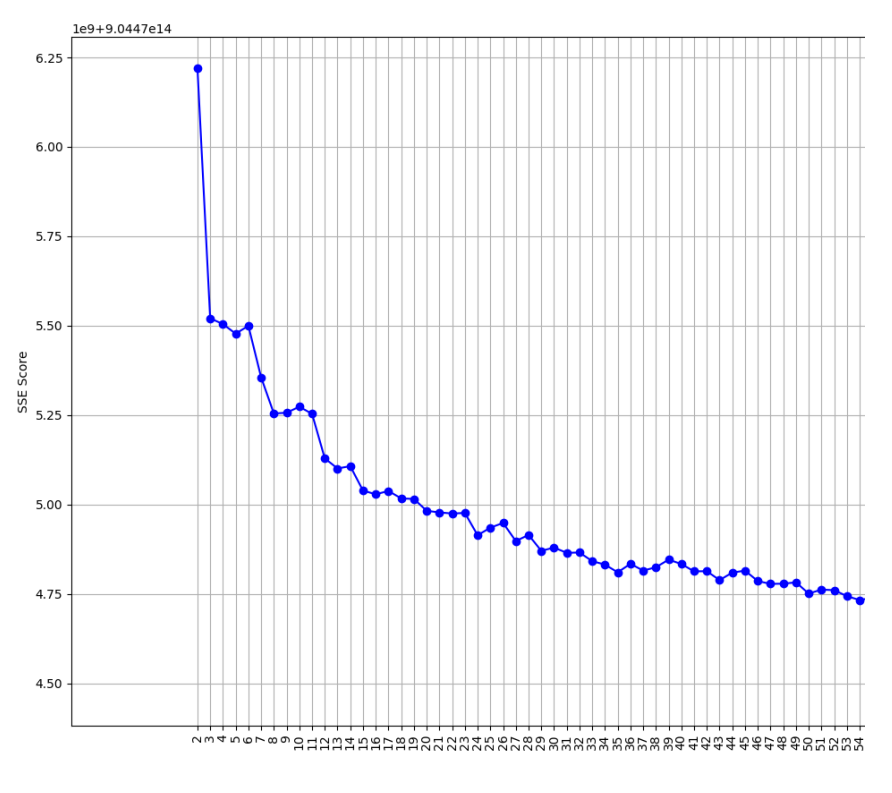
The clustering phase revealed the complexity of unsupervised learning and the challenge of finding natural groupings in high-dimensional data. Working with algorithms like kMeans, hierarchical clustering, and density-based methods like DBSCAN and HDBSCAN, I learned that different algorithms have distinct strengths and weaknesses. The consistently low Silhouette scores across most clustering attempts demonstrated that not all datasets have clear natural clusters, and sometimes domain knowledge must complement algorithmic results. This experience taught me to critically evaluate metrics rather than blindly accepting algorithmic outputs.
Classification modeling provided insights into handling multiclass problems and dealing with imbalanced datasets. The dramatic improvement in accuracy when moving from 20-class genre classification to 4-class grouped genres illustrated the importance of problem formulation and feature engineering. K-Nearest Neighbors achieved the best results for our use case, with 74% accuracy on grouped genres, demonstrating that simpler models can sometimes outperform more complex ones when properly tuned. The experience with decision trees taught me about overfitting, the importance of hyperparameter tuning, and the value of cross-validation.
The regression analysis deepened my understanding of predictive modeling for continuous variables. Working with Ridge and Lasso regularization taught me about controlling model complexity and the trade-offs between bias and variance. The disappointing results with Lasso in simple regression contexts illustrated that regularization techniques must be applied appropriately to the problem structure.
Pattern mining using Apriori and FP-Growth algorithms revealed how to extract meaningful association rules from categorical data. Learning to optimize support and confidence thresholds through iterative experimentation taught me that data mining is as much art as science. The process of binning continuous variables into categories for pattern mining highlighted the importance of thoughtful feature transformation. Most importantly, I learned that the value of data mining lies not just in implementing algorithms but in interpreting results within the domain context and communicating insights effectively.