This project is a recreation and implementation of the research paper "Word Embeddings as Statistical Estimators" by Neil Dey, Matthew Singer, Jonathan P. Williams, and Srijan Sengupta from North Carolina State University, published on arXiv in January 2023. The goal was to reproduce the theoretical framework and experimental results presented in the original paper, gaining hands-on understanding of the statistical foundations underlying word embedding methods.
The original paper investigates word embeddings through a statistical lens. Word embeddings are fundamental tools in NLP that map words and phrases to vectors in Euclidean space, enabling the application of mathematical and machine learning methods to text data. However, these embeddings have historically been evaluated primarily through downstream task performance, lacking formal theoretical understanding of what linguistic features they actually capture.
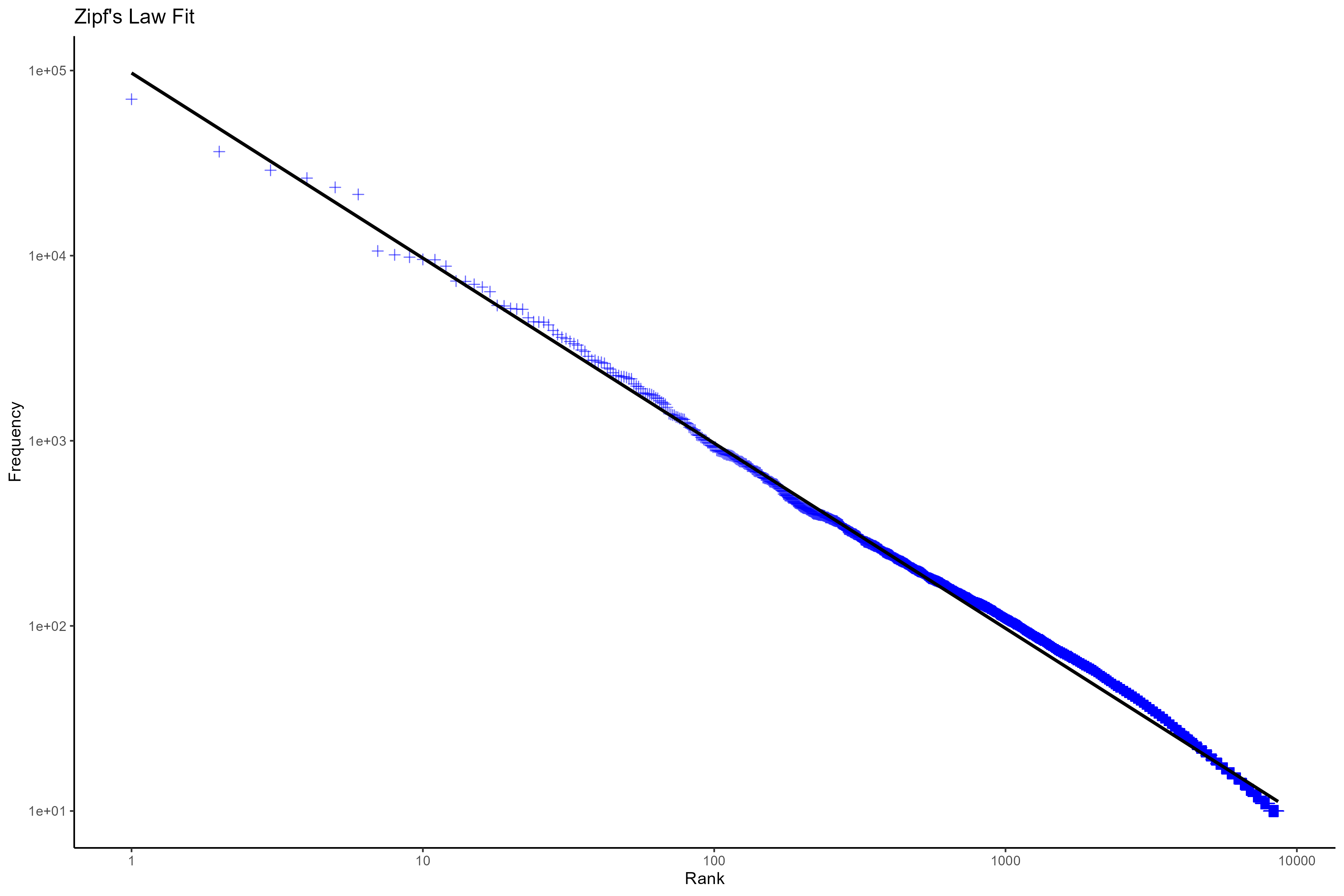
The core research question addresses whether word embeddings, particularly Word2Vec, can be formally defined and analyzed using statistical frameworks. Rather than treating embeddings as black boxes evaluated solely on performance metrics, the paper proposes defining them in statistically meaningful ways using generative models with known features. Our recreation involved implementing the proposed algorithms, generating synthetic corpora using copula-based models, and validating that embedding methods can consistently recover known features from text data.
By recreating this work, we implemented the theoretical connection between Skip-gram and Pointwise Mutual Information matrices, developed the novel SVD-based estimators including EM-MVSVD and DD-MVSVD for handling infinite PMI values which was proposed in the paper, and replicated the experimental validation using the Brown Corpus.
Through recreating this research paper, I gained insights into both the theoretical foundations and practical implementation challenges of statistical NLP. The most significant learning was understanding how Word2Vec implicitly performs matrix factorization on Pointwise Mutual Information matrices. Implementing this connection from scratch, building on Levy and Goldberg's 2014 work, transformed my perspective on embeddings from opaque neural methods to interpretable statistical estimators.
Reproducing the copula-based text generation model taught me how to work with challenging statistical concepts including Gaussian copulas combined with Zipfian marginal distributions. Understanding Sklar's Theorem and implementing the code to combine marginal distributions into joint distributions was crucial for building the dense corpus generation model. This hands-on experience showed me how theoretical statistics can be applied to create practical models that reflect real-world linguistic phenomena like Zipf's law.
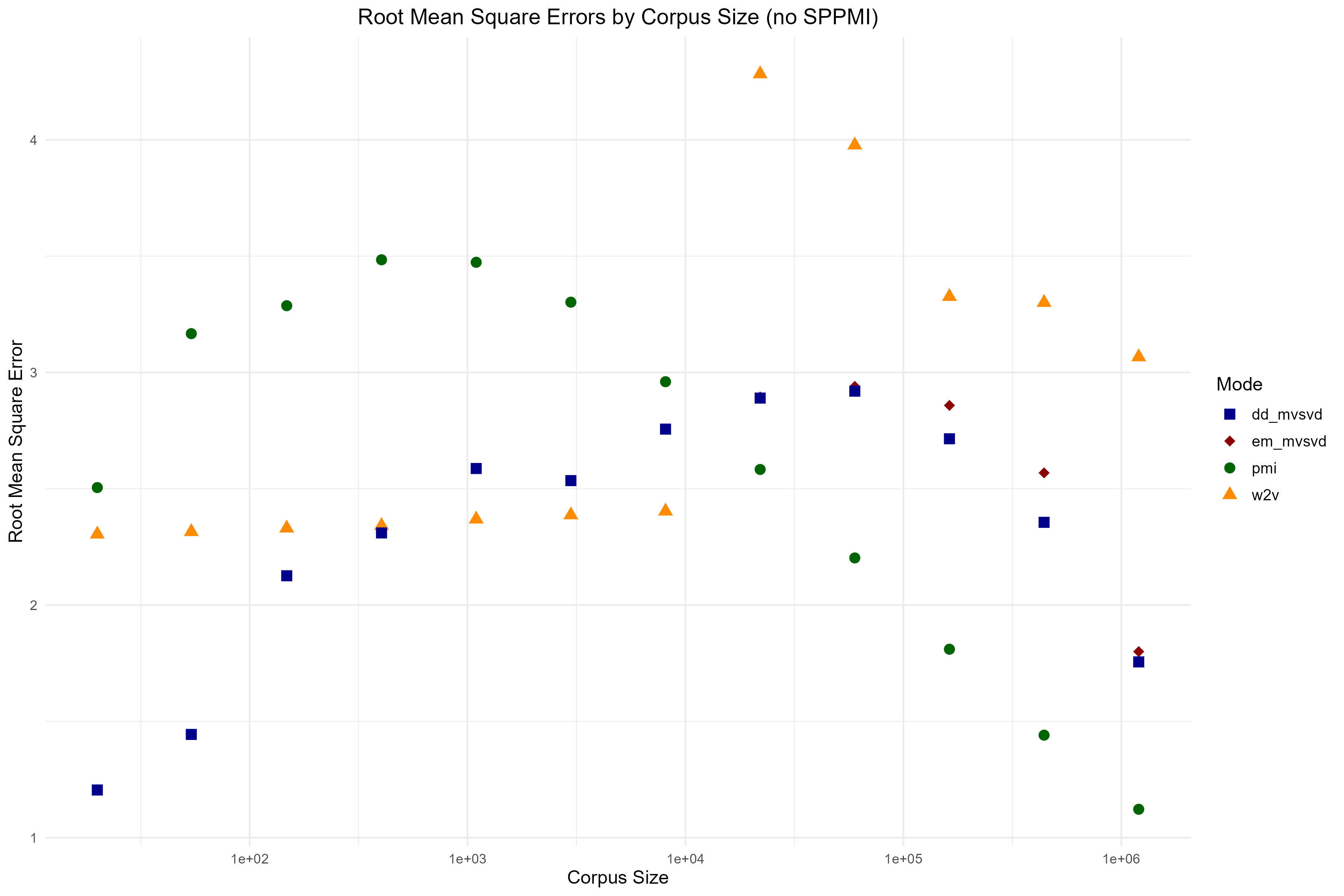
The recreation deepened my understanding of missing data problems in statistics through direct implementation. Not all missing values are created equal, the distinction between sparse settings where zeros represent true absence versus dense settings where zeros result from finite sampling has profound implications for algorithm design. Implementing the EM-MVSVD and DD-MVSVD algorithms from the paper's pseudocode gave me practical experience on statistical methods code implementation.
Working through the Expectation-Maximization algorithm implementation in the context of Singular Value Decomposition taught me how iterative optimization methods can handle complex matrix completion problems. I learned to implement exponential smoothing for convergence stabilization and understood the importance of proper initialization in iterative algorithms. Comparing my implementation results with the paper's figures validated my understanding and revealed subtleties in the algorithms that were not immediately apparent from the mathematical descriptions alone.
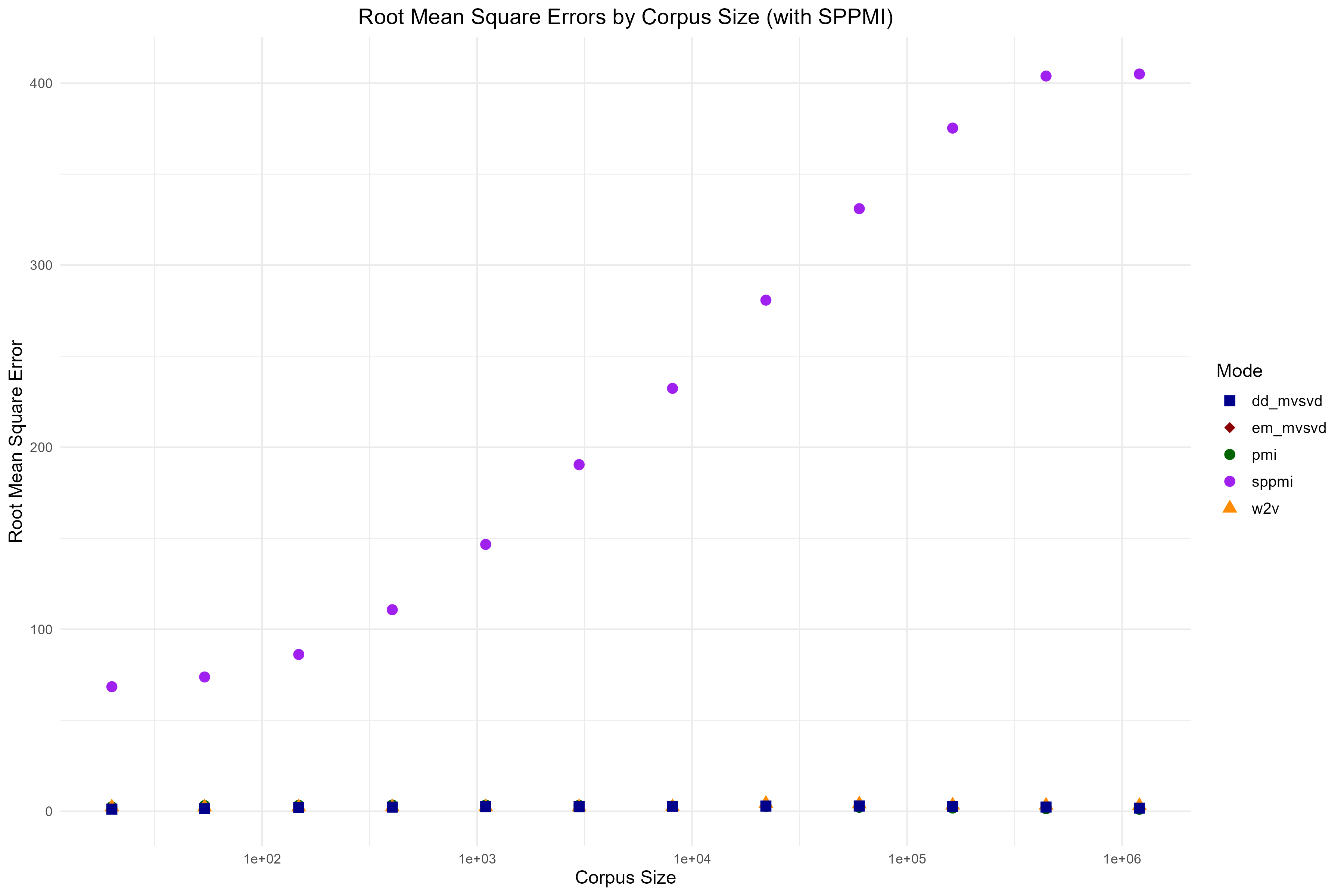
Replicating the experimental phase taught me rigorous methodology for comparing statistical estimators. I learned to generate controlled synthetic datasets where ground truth is known, enabling direct evaluation of method accuracy through RMSE measurements. Successfully reproducing the paper's key finding, that truncated SVD on SPPMI degrades with more data while MVSVD methods remain consistent, demonstrated the value of statistically principled approaches and validated my implementation.